Intelligent Thermal Control Strategy Based on Reinforcement Learning for Space Telescope
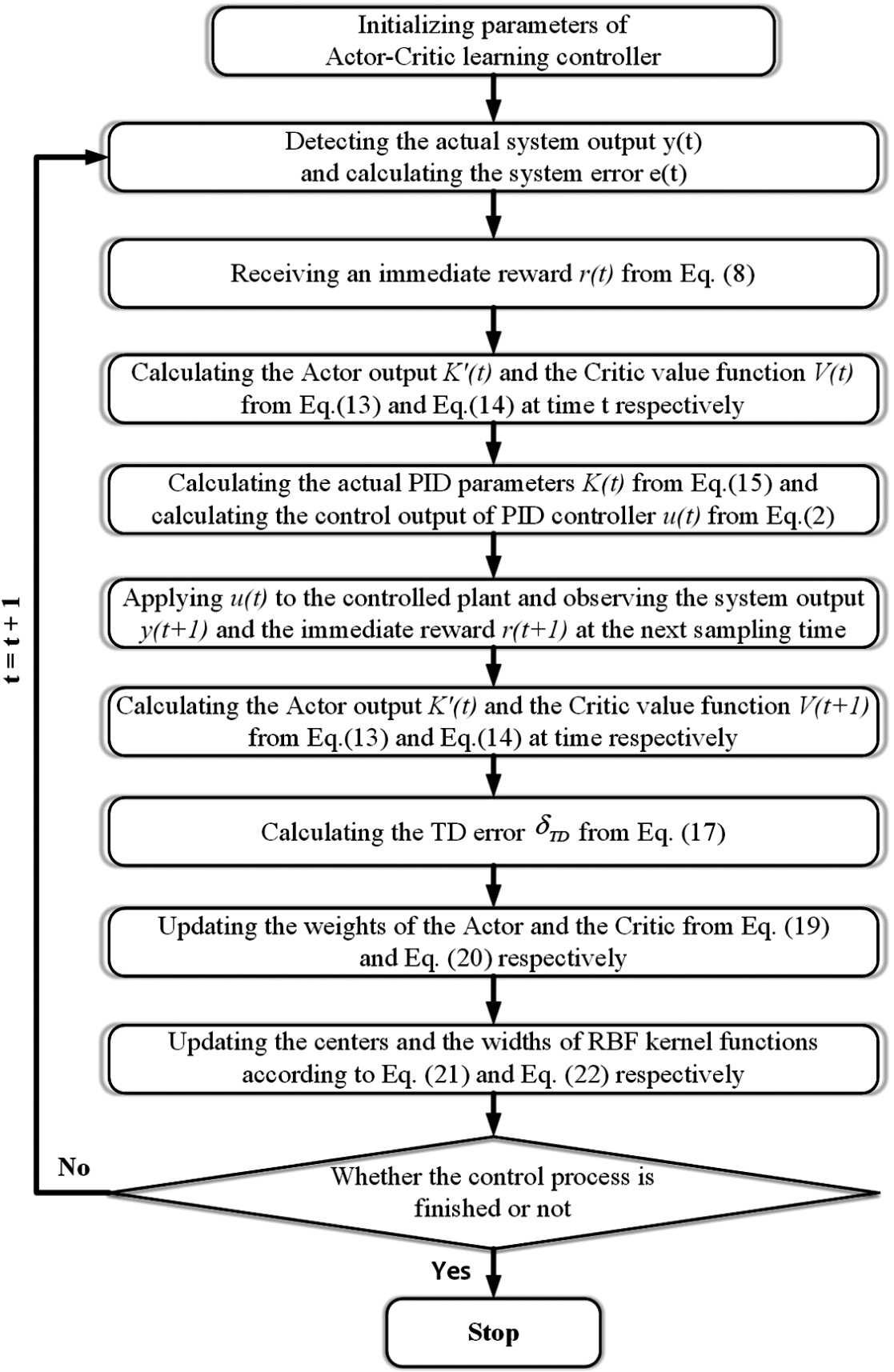
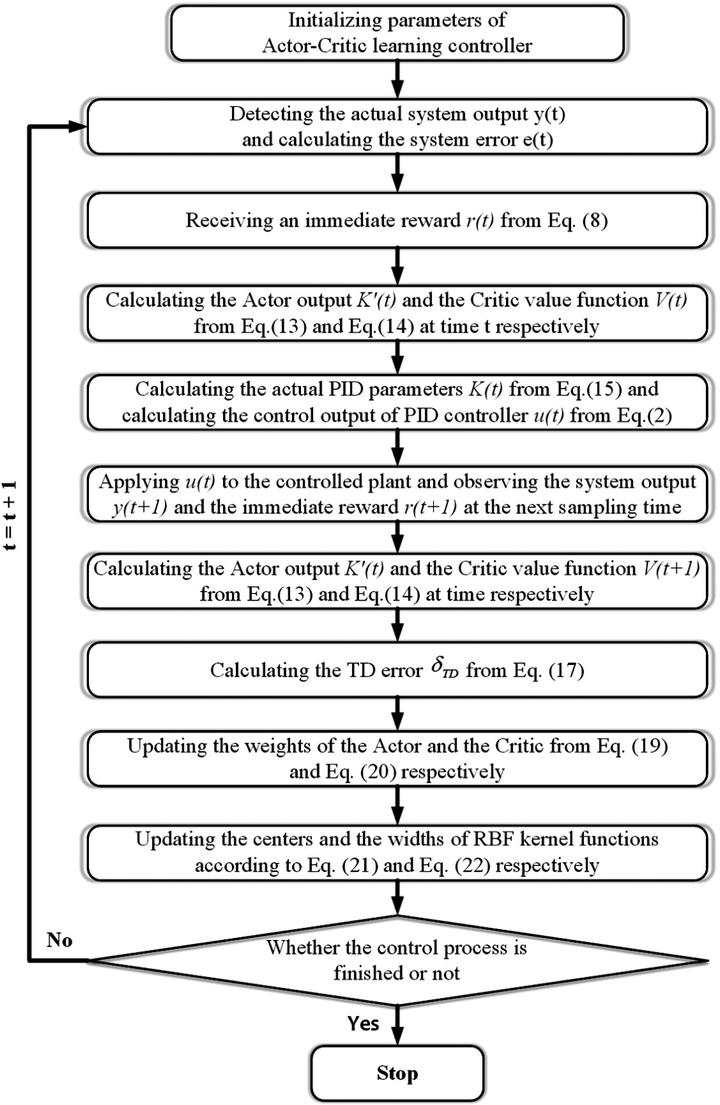 Architecture: RL PID
Architecture: RL PID
{kind=link}
Abstract
In this study, a thermal model of a space telescope is established in Simulink. An intelligent autonomous thermal control strategy based on actor-critic reinforcement learning (RL) for proportional–integral–derivative (PID) parameter adaptive self-tuning, called RL PID, is proposed. This control strategy enables the PID thermal controller to adaptively tune the PID parameters to achieve stable and precise temperature control. A single radial basis function (RBF) neural network is applied to simultaneously approximate the strategy function of the actor and the value function of the critic. The actor maps the system state to PID parameters, and the critic evaluates the output of the actor and generates a temporal difference (TD) error. Based on the architecture of the actor-critic RL algorithm and the TD error performance index, a design flow chart of RL PID is made. Both theoretical and experimental results show that RL PID can achieve a temperature control precision of 0.01°C, and that the steady-state error is reduced by 50 and 75% in the simulation and 50 and 67% in the experiment compared with those of the traditional PID controller and the traditional switch controller, respectively. RL PID has better reliability, more robustness, and a faster response.
Supplementary notes can be added here, including code, math, and images.
Yan XIONG(熊琰)
Ph.D. student from the University of Chinese Academy of Sciences
My research interests include intelligent control of gyroscopes using model-based reinforcement learning, intelligent thermal control based on deep reinforcement learning for space load, and engineering applications of AI, such as robotic systems, spacecraft strategic planning, etc.